Code organization in abstraction levels #
Initially, Penpot data model implementation was organized in a different way. We are currently in a process of reorganization. The objective is to have data manipulation code structured in abstraction layers, with well-defined boundaries, and a hierarchical structure (each level may only use same or lower levels, but not higher).
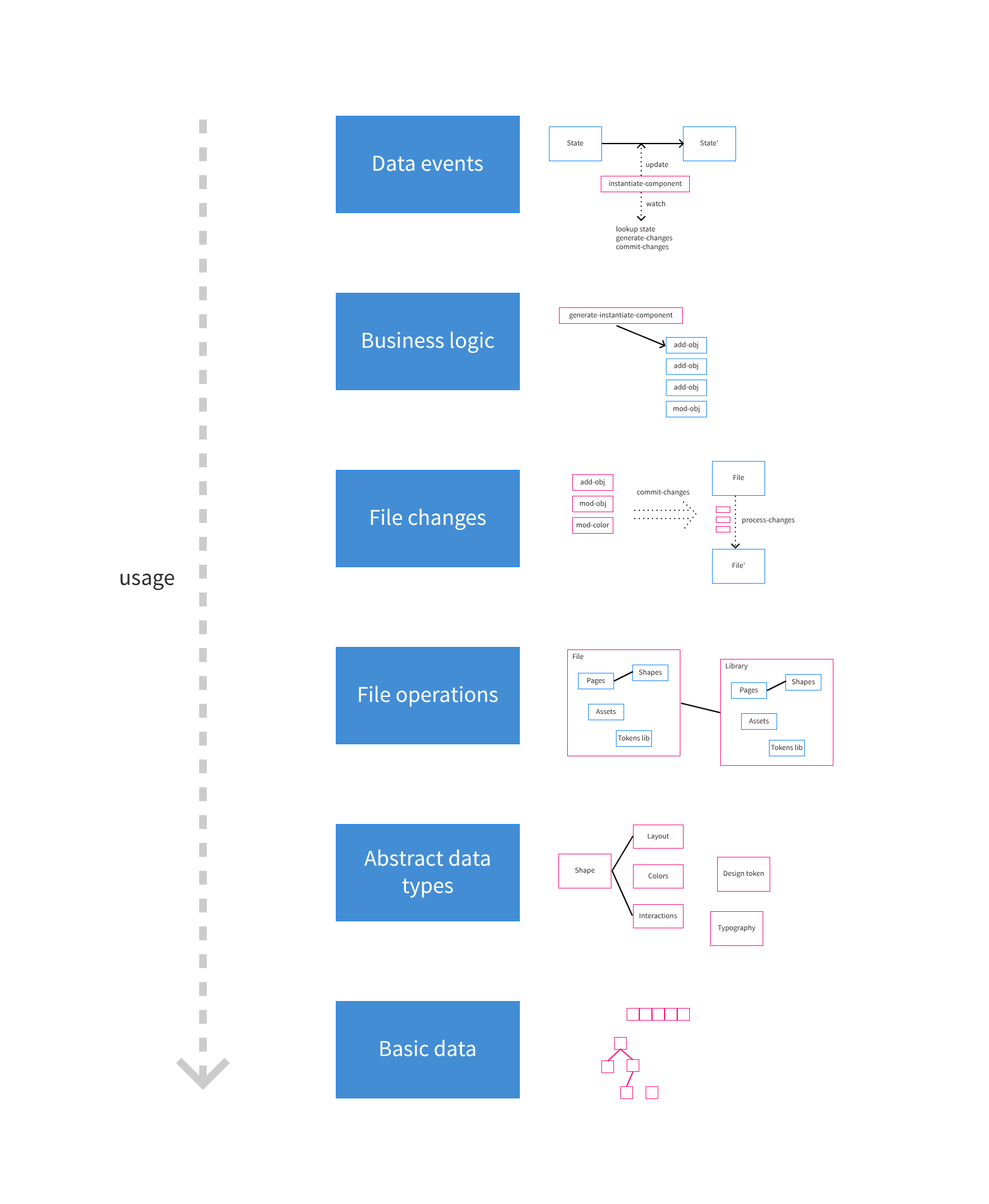
At this moment the namespace structure is already organized as described here, but there is much code that does not comply with these rules, and needs to be moved or refactored. We expect to be refactoring existing modules incrementally, each time we do an important functionality change.
Basic data #
▾ common/
▾ src/app/common/
data.cljc
▾ src/app/data/
macros.cljcA level for generic data structures or operations, that are not specifically part
of the domain model (e.g. trees, strings, maps, iterators, etc.). Also may belong
here some functions in app.common.geom/ and app.common.files.helpers.cljc.
We need to create a new directory for this and move there all functions in this leve.
Abstract data types #
▾ common/
▾ src/app/common/
▾ types/
file.cljc
page.cljc
shape.cljc
color.cljc
component.cljc
tokens_lib.cljc
...Namespaces here represent a single data entity of the domain model, or a fragment of one, as an Abstract Data Type. An ADT is a data component that is defined through a series of properties and operations, and that abstracts out the details of how it's implemented and what is the internal structure. This allows to simplify the logic of the client code, and also to make future changes in the ADT without affecting callers (if the abstract interface does not change).
Each structure in this module has:
-
A schema spec that defines the structure of the type and its values:
(def schema:fill [:map {:title "Fill"} [:fill-color {:optional true} ::ctc/rgb-color] [:fill-opacity {:optional true} ::sm/safe-number] ...) (def schema:shape-base-attrs [:map {:title "ShapeMinimalRecord"} [:id ::sm/uuid] [:name :string] [:type [::sm/one-of shape-types]] [:selrect ::grc/rect] [:points schema:points] ...) (def schema:token-set-attrs [:map {:title "TokenSet"} [:name :string] [:description {:optional true} :string] [:modified-at {:optional true} ::sm/inst] [:tokens {:optional true} [:and [:map-of {:gen/max 5} :string schema:token] [:fn d/ordered-map?]]]]) -
A protocol that define the external interface to be used for this entity.
(NOTE: this is currently only implemented in some subsystems like Design Tokens and new path handling).
(defprotocol ITokenSet (update-name [_ set-name] "change a token set name while keeping the path") (add-token [_ token] "add a token at the end of the list") (update-token [_ token-name f] "update a token in the list") (delete-token [_ token-name] "delete a token from the list") (get-token [_ token-name] "return token by token-name") (get-tokens [_] "return an ordered sequence of all tokens in the set")) -
A custom data type that implements this protocol. Functions here are the only ones allowed to modify the internal structure of the type.
Clojure allows us two kinds of custom data types:
deftype. We'll use it when we want the internal structure to be completely opaque and data accessed through protocol functions. Clojure allows access to the attributes with the(.-attr)syntax, but we prefer not to use it.defrecord. We'll use it when we want the structure to be exposed as a plain clojure map, and thus allowing to read attributes with(:attr t), to useget,keys,vals, etc. Note that this also allows modifying the object withassoc,update, etc. But in general we prefer to do all modification via protocol methods, because this way it's easier to track down where the failure is if an invalid structure is detected in a validation check, and add business logic like "updatemodified-atwhenever any other attribute is changed".
(defrecord TokenSet [name description modified-at tokens] ITokenSet (add-token [_ token] (let [token (check-token token)] (TokenSet. name description (dt/now) (assoc tokens (:name token) token)))) -
Additional helper functions the protocol should be made as small and compact as possible. If we need functions for business logic or complex queries that do not need to directly access the internal structure, but can be implemented by only calling the abstract procotol, they should be created as standalone functions. At this level, they must be functions that operate only on instances of the given domain model entity. They must always ensure the internal integrity of the data.
(defn sets-tree-seq "Get tokens sets tree as a flat list" [token-sets] ...)
IMPORTANT SUMMARY
- Code in this level only knows about one domain model entity.
- All functions ensure the internal integrity of the data.
- For this, the schema is used, and the functions must check parameters and output values as needed.
- No outside code should get any knowledge of the internal structure, so it can be changed in the future without breaking cliente code.
- All modifications of the data should be done via protocol methods (even in
defrecords). This allows a) more control of the internal data dependencies, b) easier bug tracking of corrupted data, and c) easier refactoring when the structure is modified.
Currently most of Penpot code does not follow those requirements, but it should do in new code or in any refactor.
File operations #
▾ common/
▾ src/app/common/
▾ files/
helpers.cljc
shapes_helpers.cljc
...Functions that modify a file object (or a part of it) in place, returning the file object changed. They ensure the referential integrity within the file, or between a file and its libraries.
These functions are used when we need to manipulate objects of different domain entities inside a file.
(defn resolve-component
"Retrieve the referenced component, from the local file or from a library"
[shape file libraries & {:keys [include-deleted?] :or {include-deleted? False}}]
(if (= (:component-file shape) (:id file))
(ctkl/get-component (:data file) (:component-id shape) include-deleted?)
(get-component libraries
(:component-file shape)
(:component-id shape)
:include-deleted? include-deleted?)))
(defn delete-component
"Mark a component as deleted and store the main instance shapes iside it, to
be able to be recovered later."
[file-data component-id skip-undelete? delta]
(let [delta (or delta (gpt/point 0 0))]
(if skip-undelete?
(ctkl/delete-component file-data component-id)
(-> file-data
(ctkl/update-component component-id #(load-component-objects file-data % delta))
(ctkl/mark-component-deleted component-id)))))This module is still needing an important refactor. Mainly to take functions from common.types and move them here.
File validation and repair #
There is a function in app.common.files.validate that checks a file for
referential and semantic integrity. It's called automatically when file changes
are sent to backend, but may be invoked manually whenever it's needed.
File changes objects #
▾ common/
▾ src/app/common/
▾ files/
changes_builder.cljc
changes.cljc
...This layer is how we adopt the Event sourcing pattern.
Instead of directly modifying files, we create changes
objects, that represent one modification, and that can be serialized, stored,
send to backend, logged, etc. Then it can be materialized by a processing
function, that takes a file and a change, and returns the updated file.
This also allows an important feature: undoing changes.
Processing functions should not contain business logic or algorithms. Just adapt the change interface to the operations in File or Abstract Data Types levels.
There exists a changes-builder module
with helper functions to conveniently build changes objects, and to
automatically calculate the reverse undo change.
IMPORTANT RULES
All changes must satisfy two properties:
- Idempotence. The event sourcing architecture and multiuser capability may cause that the same change may be applied more than once to a file. So changes must not, for example, be like increment counter but rather set counter to value x.
- Minimal scope. To reduce conflicts, changes should only modify the relevant part of the domain entity. This way, if a concurrent change on the same entity arrives, from another user, and it modifies a different part of the data, they may ve processed without overriding.
Business logic #
▾ common/
▾ src/app/common/
▾ logic/
shapes.cljc
libraries.cljcAt this level there are functions that implement high level user actions, in an abstract way (independent of UI). Here may be complex business logic (eg. to create a component copy we must clone all shapes, assign new ids, relink parents, change the head structure to be a copy and link each shape in the copy with the corresponding one in the main).
They don't directly modify files, but generate changes objects, that may be executed in frontend or sent to backend.
Those functions may also be composed in even higher level actions. For example a "update shape attr" action may use "unapply token" actions when the attribute has an applied token.
(defn generate-instantiate-component
"Generate changes to create a new instance from a component."
([changes objects file-id component-id position page libraries]
(generate-instantiate-component changes objects file-id component-id position page libraries nil nil nil {}))
([changes objects file-id component-id position page libraries old-id parent-id frame-id
{:keys [force-frame?]
:or {force-frame? false}}]
(let [component (ctf/get-component libraries file-id component-id)
library (get libraries file-id)
parent (when parent-id (get objects parent-id))
[...]
[new-shape new-shapes]
(ctn/make-component-instance page
component
(:data library)
position
(cond-> {}
force-frame?
(assoc :force-frame-id frame-id)))
[...]
changes
(reduce #(pcb/add-object %1 %2 {:ignore-touched true})
changes
(rest new-shapes))]
[new-shape changes])))Data events #
▾ frontend/
▾ src/app/main/data/
▾ dashboard/
▾ viewer/
▾ workspace/This is the intersection of the logic and the presentation in Penpot. Data events belong to the presentation interface and they manage the global state of the application. But they may also work on loaded files by using File or Abstract Data Types operations to query the data, and by creating and commiting changes via the Business logic generate functions.
IMPORTANT: data events must not contain business logic theirselves, or directly manipulate data structures. They only may modify or query the global state, and delegate all logic to lower level functions.
In current Penpot code, there is some quantity of business logic in data events, that should be progressively moved elsewhere as we keep refactoring.
(defn detach-component
"Remove all references to components in the shape with the given id,
and all its children, at the current page."
[id]
(dm/assert! (uuid? id))
(ptk/reify ::detach-component
ptk/WatchEvent
(watch [it state _]
(let [page-id (:current-page-id state)
file-id (:current-file-id state)
fdata (dsh/lookup-file-data state file-id)
libraries (dsh/lookup-libraries state)
changes (-> (pcb/empty-changes it)
(cll/generate-detach-component id fdata page-id libraries))]
(rx/of (dch/commit-changes changes))))))